What is Configuration Management?
Configuration management is managing all the configurations of the environments that the software application hosts.
As we know, we have different environments throughout the SDLC in DevOps starting with Unit testing, integration testing, system testing, acceptance testing, and end-user testing. So, basically, configuration management is the automated process to manage all the configurations of each of these environments.
It’s a practice that we should follow in order to keep track of all updates that are going into the system over a period of time.
This also helps in a situation where a major bug has been introduced to the system due to some new changes and we need to fix it with minimum downtime. Instead of fixing the bug, we can roll back the new changes (which caused this bug) as we have been tracking those.
Ansible, Puppet, SaltStack, and Chef are considered to be configuration management (CM) tools and were created to install and manage software on existing server instances (e.g., installation of packages, starting of services, installing scripts or config files on the instance).
What is Ansible?
Ansible is a configuration management system. It is used to set up and manage infrastructure and applications. It allows users to deploy and update applications using SSH, without needing to install an agent on a remote system.
Is Ansible an Open-Source tool?
Yes, Ansible is open source. That means you take the modules and rewrite them. Ansible is an open-source automated engine that lets you automate apps.
How does Ansible work?
Ansible is a combination of multiple pieces working together to become an automation tool. Mainly these are modules, playbooks, and plugins.
- Modules are small codes that will get executed. There are multiple inbuilt modules that serve as a starting point for building tasks.
- Playbooks contain plays which further is a group of tasks. This is the place to define the workflow or the steps needed to complete a process
- Plugins are special kinds of modules that run on the main control machine for logging purposes. There are other types of plugins also.
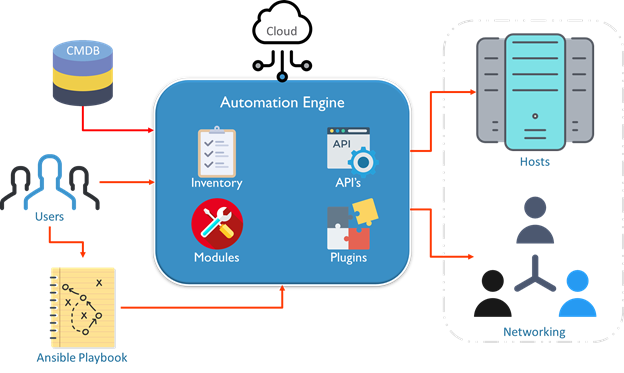
The playbooks ran via an Ansible automation engine. These playbooks contain modules that are basically actions that run in host machines. The mechanism is followed here is the push mechanism, so ansible pushes small programs to these host machines which are written to be resource models of the desired state of the system.
What are the advantages of Ansible?
Ansible has many strengths which include:
- It is agentless and only requires SSH service running on target machines.
- Python is the only required dependency and, fortunately, most systems come with it pre-installed.
- It requires minimal resources; so, there is low overhead.
- It is easy to learn and understand since Ansible tasks are written in YAML.
– Unlike other tools, most of which are procedural, Ansible is declarative; it defines the desired state and fulfills the requirements needed to achieve it.
What are the features of Ansible?
It has the following features:
- Agentless – Unlike puppet or chef there is no software or agent managing the nodes.
- Python – Built on top of python which is very easy to learn and write scripts and one of the robust programming languages.
- SSH – Passwordless network authentication which makes it more secure and easy to set up.
- Push architecture – The core concept is to push multiple small codes to the configure and run the action on client nodes.
- Setup – This is very easy to set up with a very low learning curve and any open source so that anyone can get hands-on.
- Manage Inventory – Machines’ addresses are stored in a simple text format and we can add different sources of truth to pull the list using plugins such as Openstack, Rackspace, etc.
How is Ansible used in a Continuous Delivery pipeline? Explain.
It is well known that DevOps development and operations work is integrated. This integration is very important for modern test-driven applications. Hence, Ansible integrates this by providing a stable environment for both development and operations resulting in a smooth delivery pipeline.
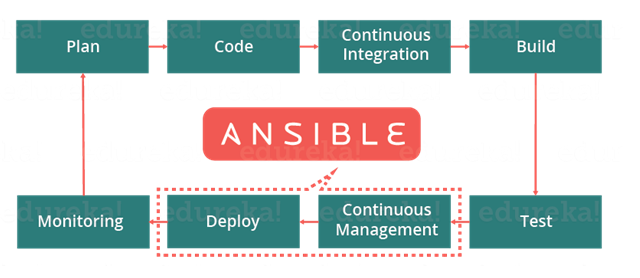
Ansible In DevOps
When developers begin to think of infrastructure as part of their application i.e as Infrastructure as code (IaC), stability and performance become normative. Infrastructure as Code is the process of managing and provisioning computing infrastructure and their configuration through machine-processable definition files, rather than physical hardware configuration or the use of interactive configuration tools. This is where Ansible automation plays a major role and stands out among its peers.
In a Continuous Delivery pipeline, Sysadmins work tightly with developers, development velocity is improved, more time is spent doing activities like performance tuning, experimenting, and getting things done, and less time is spent fixing problems.
Explain a few of the basic terminologies or concepts in Ansible
A few of the basic terms that are commonly used while operating on Ansible are:
Controller machine: The controller machine is responsible for provisioning servers that are being managed. It is the machine where Ansible is installed.
Inventory: An inventory is an initialization file that has details about the different servers that you are managing.
Playbook: It is a code file written in the YAML format. A playbook basically contains the tasks that need to be executed or automated.
Task: Each task represents a single procedure that needs to be executed, e.g., installing a library.
Module: A module is a set of tasks that can be executed. Ansible has hundreds of built-in modules but you can also create custom ones.
Role: An Ansible role is a predefined way of organizing playbooks and other files in order to facilitate sharing and reusing portions of provisioning.
Play: A task executed from start to finish or the execution of a playbook is called a play.
Facts: Facts are global variables that store details about the system such as network interfaces or operating systems.
Handlers: Handlers are used to trigger the status of a service such as restarting or stopping a service.
What are Ansible server requirements?
If you are a Windows user, then you need to have a virtual machine in which Linux should be installed. It requires Python 2.6 version or higher. If these requirements are fulfilled, then you can proceed with ease.
Please explain the difference between Ansible Playbooks and Ansible Roles
| Roles | Playbooks |
| Roles are reusable subsets of a play. | Playbooks contain Plays. |
| A set of tasks for accomplishing a certain role. | Mapps among hosts and roles. |
| Example: common, webservers. | Example: site.yml, fooservers.yml, webservers.yml. |
What is the difference between a playbook and a play and mention command to run playbook?
A playbook is a list of plays. A play is a set of tasks and roles that run on one or more managed hosts. Play includes one or more tasks.
Command to execute a playbook > To execute a playbook use the Ansible playbook command
Syntax: ansible-playbook playbookName.yml
What are Ansible tasks?
The task is a unit action of Ansible. It helps by breaking a configuration policy into smaller files or its code. These blocks can be used in automating a process. For example, to install a package or update a software
Install <package_name>, update <software_name>
What is a playbook?
A playbook has a series of YAML-based files that send commands to remote computers via scripts. Developers can configure complete complex environments by passing a script to the required systems rather than using individual commands to configure computers from the command line remotely. Playbooks are one of Ansible’s strongest selling points and are often referred to as Ansible’s building blocks.
Where are tags used?
A tag is an attribute that sets the Ansible structure, plays, tasks, and roles. When an extensive playbook is needed, it is more useful to run just a part of it as opposed to the entire thing. That is where tags are used.
Can you create reusable content with Ansible?
Yes, Ansible has the concept of roles that helps to create reusable content. To create a role, you need to follow Ansible’s conventions of structuring directories and naming files.
Can you build your own modules with Ansible?
Yes, we can create or own modules within Ansible.
It is an open-source tool that primarily works on Python. If you are good at programming in Python you can start creating your own modules in a few hours from scratch and you don’t need to have any prior knowledge of the same.
How can you connect other devices within Ansible?
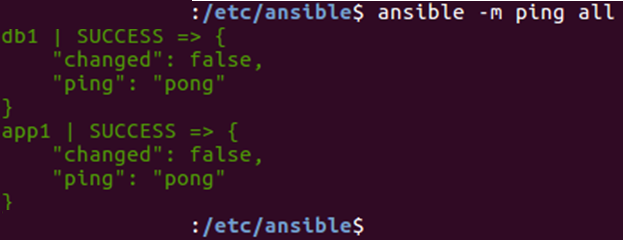
Once Ansible is installed on the controlling machines, an inventory(hosts) file is created. This inventory file specifies the connection between other nodes. A connection can be made using a simple SSH. To check the connection to a different device, you can use the ping module.
ansible -m ping all
The above command checks the connection to all the nodes specified in the inventory file.
To set up hosts you need to edit the host’s(inventory) file in the Ansible directory

Syntax: sudo nano /etc/ansible/hosts

- Change your directory to /etc/Ansible
- Now you can check if Ansible’s connection with your hosts in your inventory file is good
- Use the Ansible’s ping module to check whether or not Ansible is connecting to hosts
Syntax: ansible –m ping <hosts>
What is Ansible Galaxy?
Ansible Galaxy is a tool to create role, this tool comes bundled with Ansible.
Galaxy is a repository of Ansible roles that can be shared among users and can be directly dropped into playbooks for execution. It is also used for the distribution of packages containing roles, plugins, and modules also known as collection. The ansible-galaxy-collection command implements like init, build, install, etc like an ansible-galaxy command.
Explain Role folder contents
Roles:
- To create a role a tool called Ansible-galaxy comes bundled with Ansible
- Syntax: ansible-galaxy init roleName
![]()
- The defaults folder contains a file called main.yml
- This main.yml file contains all the default variables to be used by the role
- Files houses all the files which are to be added to the host machine being configured
- The files in the Files directory can be referenced through copy task
- Files cannot be modified while being added to the host machine
- All the handlers that may be used in the roles are kept in this directory
- The meta folder houses another main.yml file
- The main.yml file consists of metadata such as contributing author, dependencies, platforms, etc.
- Tasks contains the playbooks used by the role
- Templates contains files which can be modified and added to the host being provisioned
- Jinja2(template language) is used to achieve the modifications
- Vars also holds variables like defaults does
- The variables in vars have a higher priority compared to default variables
- Vars variables are difficult to override
- Roles can be called inside a playbook
- All the logic of the role becomes the part of the playbook using it
—
– hosts: wordpress_hosts
roles:
– nginx
– php
– mysql
– wordpress
What are the variables in Ansible?
Variables in Ansible are very similar to variables in any programming language. Like any other variable, an Ansible variable is assigned a value used in computing playbooks. You can also use conditions around the variables. Here’s an example:
| 1
2 3 |
– hosts: your hosts
– vars: – port_Tomcat : 8080 |
Here, we’ve defined a variable called port_Tomcat and assigned port number 8080 to it. Such a variable can be used in the Ansible Playbook.
Compare Ansible VS Puppet
| Ansible | Puppet |
| Simplest Technology | Complex Technology |
| Written in YAML language | Written in Ruby language |
| Automated workflow for Continuous Delivery | Visualization and reporting |
| Agent-less install and deploy | Easy install |
| GUI -work under progress | Good GUI |
| CLI accepts commands in almost any language | Must learn the Puppet DSL |
Compare Ansible vs Chef?
| Ansible | Chef |
| Ansible is easier to set up and provides faster performance | Compared to Ansible, Chef is not very easy to set up |
| Ansible uses YAML (Python) for managing configurations | Chef uses DSL (Ruby) for managing configurations |
| Highly scalable | Highly scalable |
| Ansible charges annually $10,000 | Chef Automate charges an annual fee of $13700 |
Which protocol does Ansible use to communicate with Linux and Windows?
For Linux, the protocol used is SSH.
For Windows, the protocol used is WinRM.
Ansible can be used to manage and execute core functions in Windows environments, from security updates to remote management using WinRM. Although Ansible must be run on Linux, Windows administrators can use Ansible to manage and automate their systems without needing to know how to use a Linux terminal.
Ansible includes native Windows support that uses Windows PowerShell remoting to manage Windows in a way that will feel familiar to Windows administrators.
How will you get access to the ansible host when I delegate a task?
We can access it through host variables and even works for all the overridden variables like ansible_port, ansible_user, etc.
original_host: “{{ hostvars[inventory_hostname][‘ansible_host’] }}”
What are ad hoc commands? Give an example
Ad hoc commands are simple one-line commands used to perform a certain task. You can think of ad hoc commands as an alternative to writing playbooks. An example of an ad hoc command is as follows:
Command: ansible host -m netscaler -a “nsc_host=nsc.example.com user=apiuser password=apipass”
What is Ansible-doc?
Ansible-doc displays information on modules installed in Ansible libraries. It displays a listing of plug-ins and their short descriptions, provides a printout of their documentation strings, and creates a short snippet that can be pasted into a playbook.
Explain Ansible modules in detail.
Ansible modules are like functions or standalone scripts which run specific tasks idempotently. The return value of these are JSON string in stdout and input depends on the type of module. These are used by Ansible playbooks.
There are 2 types of modules in Ansible:
- Core Modules
The core Ansible team is responsible for maintaining these modules thus these come with Ansible itself. The issues reported are fixed on priority than those in the “extras” repo.
- Extras Modules
The Ansible community maintains these modules so, for now, these are being shipped with Ansible but they might get discontinued in the future. These can be used but if there are any feature requests or issues they will be updated on low priority.
Now popular extra modules might enter into the core modules anytime. You may find these separate repos for these modules as ansible-modules-core and ansible-modules-extra respectively.
What is a YAML file and how do we use it in Ansible?
YAML or files are like any formatted text file with few sets of rules just like JSON or XML. Ansible uses this syntax for playbooks as it is more readable than other formats.
An example of JSON vs YAML is:
JSON
{
“object”: {
“key”: “value”,
“array”: [
{
“null_value”: null
},
{
“boolean”: true
},
{
“integer”: 1
},
{
“alias”: “aliases are like variables”
}
]
}
}
YAML
object:
key: value
array:
– null_value:
– boolean: true
– integer: 1
– alias: aliases are like variables
How to use YAML files in high programming languages such as JAVA, Python, etc?
YAML is supported in most programming languages and can be easily integrated with user programs.
In JAVA we can use the Jackson module which also parses XML and JSON. For e.g
// We need to declare Topic class with necessary attributes such as name, total_score, user_score, sub_topics
List<Topic> topics = new ArrayList<Topic>();
topics.add(new Topic(“String Manipulation”, 10, 6));
topics.add(new Topic(“Knapsack”, 5, 5));
topics.add(new Topic(“Sorting”, 20, 13));
// We want to save this Topic in a YAML file
Topic topic = new Topic(“DS & Algo”, 35, 24, topics);
// ObjectMapper is instantiated just like before
ObjectMapper om = new ObjectMapper(new YAMLFactory());
// We write the `topic` into `topic.yaml`
om.writeValue(new File(“/src/main/resources/topics.yaml”), topic);
—
name: “DS & Algo”
total_score: 35
user_score: 24
sub_topics:
– name: “String Manipulation”
total_score: 10
user_score: 6
– name: “Knapsack”
total_score: 5
user_score: 5
– name: “Sorting”
total_score: 20
user_score: 13
Similarly, we can read from YAML also:
// Loading the YAML file from the /resources folder
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
File file = new File(classLoader.getResource(“topic.yaml”).getFile());
// Instantiating a new ObjectMapper as a YAMLFactory
ObjectMapper om = new ObjectMapper(new YAMLFactory());
// Mapping the employee from the YAML file to the Employee class
Topic topic = om.readValue(file, Topic.class);
In python similarly, we can use the pyyaml library and read and write easily in YAML format.
How to setup a jump host to access servers having no direct access?
First, we need to set a ProxyCommand in ansible_ssh_common_args inventory variable, since any arguments specified in this variable are added to the sftp/scp/ssh command line when connecting to the relevant host(s). For example
[gatewayed]
staging1 ansible_host=10.0.2.1
staging2 ansible_host=10.0.2.2
To create a jump host for these we need to add a command in ansible_ssh_common_args
ansible_ssh_common_args: ‘-o ProxyCommand=”ssh -W %h:%p -q user@gateway.example.com”‘
In this way whenever we will try to connect to any host in the gatewayed group ansible will append these arguments to the command line.
Suppose you’re using Ansible to configure the production environment and your playbook uses an encrypted file. Encrypted files prompt the user to enter passwords. But since Ansible is used for automation, can this process be automated?
Yes, Ansible uses a feature called password file, where all the passwords to your encrypted files can be saved. So each time the user is asked for the password, he can simply make a call to the password file. The password is automatically read and entered by Ansible.
$ ansible-playbook launch.yml –vault-password-file ~/ .vault_pass.txt
Having a separate script that specifies the passwords is also possible. You need to make sure the script file is executable and the password is printed to standard output for it to work without annoying errors.
What are callback plugins in Ansible?
Callback plugins basically control most of the output we see while running cmd programs. But it can also be used to add additional output. For example log_plays callback is used to record playbook events to a log file, and mail callback is used to send email on playbook failures. We can also add custom callback plugins by dropping them into a callback_plugins directory adjacent to play, inside a role, or by putting it in one of the callback directory sources configured in ansible.cfg.
What is Ansible Inventory and its types?
In Ansible, there are two types of inventory files: Static and Dynamic.
- Static inventory file is a list of managed hosts declared under a host group using either hostnames or IP addresses in a plain text file. The managed host entries are listed below the group name in each line. For example
[gatewayed]
staging1 ansible_host=10.0.2.1
staging2 ansible_host=10.0.2.2
- Dynamic inventory is generated by a script written in Python or any other programming language or by using plugins(preferable). In a cloud setup, static inventory file configuration will fail since IP addresses change once a virtual server is stopped and started again. We create a demo_aws_ec2.yaml file for the config such as
plugin: aws_ec2 regions:
ap-south-1 filters:
tag:tagtype: testing
Now we can fetch using this command
ansible-inventory -i demo_aws_ec2.yaml -graph
How can I display all the inventory vars defined for my host?
In order to check the inventory vars resulting from what you’ve defined in the inventory, you can execute the below command:
ansible -m debug -a “var=hostvars[‘hostname’]” localhost
What is Ansible Vault?
Ansible vault is used to keep sensitive data such as passwords instead of placing it as plaintext in playbooks or roles. Any structured data file or any single value inside the YAML file can be encrypted by Ansible.
To encrypt a file
ansible-vault encrypt foo.yml bar.yml baz.yml
And similarly to decrypt
ansible-vault decrypt foo.yml bar.yml baz.yml
How can looping be done over a list of hosts in a group, inside of a template?
This can be done by accessing the “$groups” dictionary in the template, like so:
{% for host in groups[‘db_servers’] %}
{{ host }}
{% endfor %}
If we need to access facts also we need to make sure that the facts have been populated. For instance, a play that talks to db_servers:
– hosts: db_servers
tasks:
– debug: msg=”Something to debug”
Now, this can be used within a template, like so:
{% for host in groups[‘db_servers’] %}
{{ hostvars[host][‘ansible_eth0’][‘ipv4’][‘address’] }}
{% endfor %}.
What is the ad-hoc command in Ansible?
Ad-hoc commands are like one-line playbooks to perform a specific task only. The syntax for the ad-hoc command is
ansible [pattern] -m [module] -a “[module options]”
For example, we need to reboot all servers in the staging group
ansible atlanta -a “/sbin/reboot” -u username –become [–ask-become-pass]
-
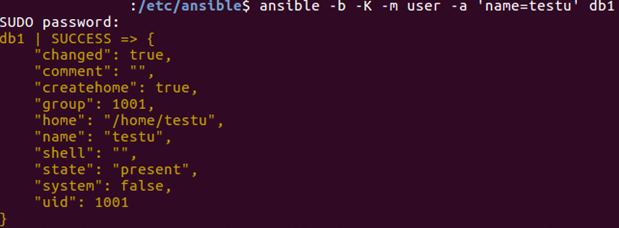
- Adding a user to a host using an Ansible ad-hoc command
Install Nginx using Ansible playbook?
The playbook file would be:
– hosts: stagingwebservers
gather_facts: False
vars:
– server_port: 8080
tasks:
– name: install nginx
apt: pkg=nginx state=installed update_cache=true
– name: serve nginx config
template: src=../files/flask.conf dest=/etc/nginx/conf.d/
notify:
– restart nginx
handlers:
– name: restart nginx
service: name=nginx state=restarted
– name: restart flask app
service: name=flask-demo state=restarted
…
In the above playbook, we are fetching all hosts of stagingwebservers group for executing these tasks. The first task is to install Nginx and then configure it. We are also taking a flask server for reference. In the end, we also defined handlers so that in case the state changes it will restart Nginx. After executing the above playbook we can verify whether Nginx is installed or not.
ps waux | grep nginx
How do I access a variable name programmatically?
Variable names can be built by adding strings together. For example, if we need to get ipv4 address of an arbitrary interface, where the interface to be used may be supplied via a role parameter or other input, we can do it in this way.
{{ hostvars[inventory_hostname][‘ansible_’ + which_interface][‘ipv4’][‘address’] }}
What is Ansible Tower and what are its features?
Ansible Tower is an enterprise-level solution by RedHat. It provides a web-based console and REST API to manage Ansible across teams in an organization. There are many features such as
- Workflow Editor – We can set up different dependencies among playbooks, or running multiple playbooks maintained by different teams at once
- Real-Time Analysis – The status of any play or tasks can be monitored easily and we can check what’s going to run next
- Audit Trail – Tracking logs are very important so that we can quickly revert back to a functional state if something bad happens.
- Execute Commands Remotely – We can use the tower to run any command to a host or group of hosts in our inventory.
There are other features also such as Job Scheduling, Notification Integration, CLI, etc.
Can you keep data secret in the playbook?
The following playbook might come in handy if you want to keep secret any task in the playbook when using -v (verbose) mode:
– name: secret task
shell: /usr/bin/do_something –value={{ secret_value }}
no_log: True
It hides sensitive information from others and provides the verbose output.
Explain how you will copy files recursively onto a target host?
There’s a copy module that has a recursive parameter in it but there’s something called synchronize which is more efficient for large numbers of files.
For example:
– synchronize:
src: /first/absolute/path
dest: /second/absolute/path
delegate_to: “{{ inventory_hostname }}”
What is the best way to make Content Reusable/ Redistributable?
To make content reusable and redistributable Ansible roles can be used. Ansible roles are basically a level of abstraction to organize playbooks. For example, if we need to execute 10 tasks on 5 systems, writing all of them in the playbook might lead to blunders and confusion. Instead we create 10 roles and call them inside the playbook.
What are handlers?
Handlers are like special tasks which only run if the Task contains a “notify” directive.
tasks:
– name: install nginx
apt: pkg=nginx state=installed update_cache=true
notify:
– start nginx
handlers:
– name: start nginx
service: name=nginx state=started
In the above example after installing NGINX we are starting the server using a `start nginx` handler.
How do you use Ansible to create encrypted files?
To create an encrypted file, use the ‘ansible-vault create’ command.
$ ansible-vault create filename.yaml
You will get a prompt to create a password, and then to type it again for confirmation. You will now have access to a new file, where you can add and edit data.
How do we write an Ansible handler with multiple tasks?
Suppose you want to create a handler that restarts a service only if it is already running.
Handlers can understand generic topics, and tasks can notify those topics as shown below. This functionality makes it much easier to trigger multiple handlers. It also decouples handlers from their names, making it easier to share handlers among playbooks and roles.
– name: Check if restarted
shell: check_is_started.sh
register: result
listen: Restart processes
– name: Restart conditionally step 2
service: name=service state=restarted
when: result
listen: Restart processes
How to generate encrypted passwords for a user module?
Ansible has a very simple ad-hoc command for this
ansible all -i localhost, -m debug -a “msg={{ ‘mypassword’ | password_hash(‘sha512’, ‘mysecretsalt’) }}”
We can also use the Passlib library of Python, e.g
python -c “from passlib.hash import sha512_crypt; import getpass; print(sha512_crypt.using(rounds=5000).hash(getpass.getpass()))”
On top of this, we should also avoid storing raw passwords in playbook or host_vars, instead, we should use integrated methods to generate a hash version of a password.
How does dot notation and array notation of variables are different?
Dot notation works fine unless we stump upon few special cases such as
- If the variable contains a dot(.), colon(:), starting or ending with an underscore or any known public attribute.
- If there’s a collision between methods and attributes of python dictionaries.
- Array notation also allows for dynamic variable composition.
Do you have any idea of how to turn off the facts in Ansible?
If you do not need any factual data about the hosts and know everything about the systems centrally, we can turn off fact gathering. This has advantages in scaling Ansible in push mode with very large numbers of systems, mainly, or if we are using Ansible on experimental platforms.
Command:
– hosts: whatever
gather_facts: no
How does Ansible synchronize module works?
Ansible synchronize is a module similar to rsync in Linux machines which we can use in playbooks. The features are similar to rsync such as archive, compress, delete, etc but there are few limitations also such as
- Rsync must be installed on both source and target systems
- Need to specify delegate_to to change the source from localhost to some other port
- Need to handle user permission as files are accessible as per remote user.
- We should always give the full path of the destination host location in case we use sudo otherwise files will be copied to the remote user home directory.
- Linux rsync limitations related to hard links are also applied here.
- It forces -delay-updates to avoid the broken state in case of connection failure
An example of synchronize module is
—
– hosts: host-remote tasks:
– name: sync from sync_folder
synchronize:
src: /var/tmp/sync_folder dest: /var/tmp/
Here we are transferring files of /var/tmp/sync_folder folder to remote machine’s /var/tmp folder
How does the Ansible firewalld module work?
Ansible firewalld is used to manage firewall rules on host machines. This works just as Linux firewalld daemon for allowing/blocking services from the port. It is split into two major concepts
- Zones: This is the location for which we can control which services are exposed to or a location to which one the local network interface is connected.
- Services: These are typically a series of port/protocol combinations (sockets) that your host may be listening on, which can then be placed in one or more zones
Few examples of setting up firewalld are
– name: permit traffic in default zone for https service
ansible.posix.firewalld:
service: https
permanent: yes
state: enabled
– name: do not permit traffic in default zone on port 8081/tcp
ansible.posix.firewalld:
port: 8081/tcp
permanent: yes
state: disabled
How is the Ansible set_fact module different from vars, vars_file, or include_var?
In Ansible, set_fact is used to set new variable values on a host-by-host basis which is just like ansible facts, discovered by the setup module. These variables are available to subsequent plays in a playbook. In the case of vars, vars_file, or include_var we know the value beforehand whereas when using set_fact, we can store the value after preparing it on the fly using certain tasks like using filters or taking subparts of another variable. We can also set a fact cache over it.
set_fact variable assignment is done by using key-pair values where the key is the variable name and the value is the assignment to it. A simple example will be like below
– set_fact:
one_fact: value1
second_fact:
value2
When is it unsafe to bulk-set task arguments from a variable?
All of the task’s arguments can be dictionary-typed variables which can be useful in some dynamic execution scenarios also. However, Ansible issues a warning since it introduces a security risk.
vars:
usermod_args:
name: testuser
state: present
update_password: always
tasks:
– user: ‘{{ usermod_args }}’
In the above example, the values passed to the variable usermod_args could be overwritten by some other malicious values in the host facts on a compromised target machine. To avoid this
- bulk variable precedence should be greater than host facts.
- need to disable INJECT_FACTS_AS_VARS configuration to avoid collision of fact values with variables.
Explain Ansible register.
Ansible register is used to store the output from task execution in a variable. This is useful when we have different outputs from each remote host. The register value is valid throughout the playbook execution so we can make use of set_fact to manipulate the data and provide input to other tasks accordingly.
– hosts: all tasks:
name: find all txt files in /home shell: “find /home -name *.txt” register: find_txt_files
debug:
var: find_txt_files
In the above example, we are searching for all .txt files in the remote host’s home folder and then capturing it in find_txt_files and displaying that variable.
How can we delegate tasks in Ansible?
Task delegation is an important feature of Ansible since there might be use cases where we would want to perform a task on one host with reference to other hosts. We can do this using the delegate_to keyword.
For example, if we want to manage nodes in a load balancer pool we can do:
– hosts: webservers
serial: 5
tasks:
– name: Take machine out of ELB pool
ansible.builtin.command: /usr/bin/take_out_of_pool {{ inventory_hostname }}
delegate_to: 127.0.0.1
– name: Actual steps would go here
ansible.builtin.yum:
name: acme-web-stack
state: latest
– name: Add machine back to ELB pool
ansible.builtin.command: /usr/bin/add_back_to_pool {{ inventory_hostname }}
delegate_to: 127.0.0.1
We are also defining serial to control the number of hosts executing at one time. There is another shorthand syntax called local_action which can be used instead of delegate_to.
…
tasks:
– name: Take machine out of ELB pool
local_action: ansible.builtin.command /usr/bin/take_out_of_pool {{ inventory_hostname }}
…
But there are few exceptions also such as include, add_host, and debug tasks that cannot be delegated
By default, the Ansible reboot module waits for how many seconds. Is there any way to increase it?
By default, the Ansible reboot module waits 600 seconds. Yes, it is possible to increase Ansible reboot to certain values. The syntax given-below can be used for the same:
– name: Reboot a Linux system
reboot:
reboot_timeout: 1200
What do you understand by the term idempotency?
Idempotency is an important Ansible feature. It prevents unnecessary changes in managed hosts. With idempotency, we can execute one or more tasks on a server as many times as we need to, but it will not change anything that has already been modified and is working correctly.
To put it simply, the only changes added are the ones needed and not already in place.
How can you create a LAMP stack and deploy a webpage by using Ansible?
Suppose you’re trying to deploy a website on 30 systems, every website deployment will require a base OS, web-server, Database, and PHP. We use ansible playbook to install these prerequisites on all 30 systems at once.
For this particular problem statement, you can use two virtual machines, one as a server where Ansible is installed and the other machine acts as the remote host. Also, I’ve created a simple static webpage saved in a folder index which has two files, index.html, and style.css.
In the below code I’ve created a single Ansible playbook to install Apache, MySql, and PHP:
# Setup LAMP Stack
– hosts: host1
tasks:
– name: Add ppa repository
become: yes
apt_repository: repo=ppa:ondrej/php
– name: Install lamp stack
become: yes
apt:
pkg:
– apache2
– mysql-server
– php7.0
– php7.0-mysql
state: present
update cache: yes
– name: start apache server
become: yes
service:
name: apache2
state: started
enabled: yes
– name: start mysql service
become: yes
services:
name: mysql
state: started
enabled: yes
– name: create target directory
file: path=/var/www/html state=directory mode=0755
– name: deploy index.html
became: yes
copy:
src: /etc/ansible/index/index.html
dest: var/www/html/index/index.html
Now, there are 6 main tasks, each task performs a specific function:
- The first task adds the repository required to install MySQL and PHP.
- The second task installs apache2, MySQL-server, PHP, and PHP-MySQL.
- The third and fourth task starts the Apache and MySQL service.
- The fifth task creates a target directory in the host machine and
- Finally, the sixth task executes the index.html file, it picks up the file from the server machine and copies it into the host machine.
To finally run this playbook you can use the following command:
$ ansible-playbook lamp.yml -K
How do I set the PATH or any other environment variable for a task?
The environment variables can be set by using the ‘environment’ keyword. It can be set for either a task or an entire playbook as well.
Follow the below code snippet to see how:
environment:
PATH: “{{ ansible_env.PATH }}:/thingy/bin”
SOME: value
How can you handle different machines needing different user accounts or ports to log in with?
The simplest way to do this is by setting inventory variables in the inventory file.
Let’s consider that these hosts have different usernames and ports:
[webservers]
asdf.example.com ansible_port=5000 ansible_user=alice
jkl.example.com ansible_port=5001 ansible_user=bob
Also, if you wish to, you can specify the connection type to be used:
[testcluster]
localhost ansible_connection=local
/path/to/chroot1 ansible_connection=chroot
foo.example.com ansible_connection=paramiko
To make this more clear it is best to keep these in group variables or file them in a group_vars/<group-name> file.
How do you test Ansible projects?
There are three testing methods available:
- Asserts: Asserts duplicates how the test runs in other languages like Python. It verifies that your system has reached the actual intended state, and not just as a simulation that you would find in check mode. Asserts shows that the task did the job it was supposed to do and changed the appropriate resources.
- Check mode: Check mode shows you how everything would run without the simulation. Therefore, you can easily see if the project behaves the way we expected it to. The limitation is that check mode does not run the scripts and commands used in the roles and playbooks. To get around this, we have to disable check mode for specific tasks by running.
- Command: check_mode: no
- Manual run: Just run the play and verify that the system is in its desired state. This testing choice is the easiest method, but it carries an increased risk because it results in a test environment that may not be similar to the production environment.
Does Ansible support AWS?
Ansible has hundreds of modules supporting AWS and some of them include:
- Autoscaling groups
- CloudFormation
- CloudTrail
- CloudWatch
- DynamoDB
- ElastiCache
- Elastic Cloud Compute (EC2)
- Identity Access Manager (IAM)
- Lambda
- Relational Database Service (RDS)
- Route53
- Security Groups
- Simple Storage Service (S3)
- Virtual Private Cloud (VPC)
Can you copy files recursively onto a target host? If yes, how?
Yes, you can copy files recursively onto a target host using the copy module. It has a recursive parameter that copies files from a directory. There is another module called synchronize which is specifically made for this.
– synchronize:
src: /first/absolute/path
dest: /second/absolute/path
delegate_to: “{{ inventory_hostname }}”
Write a playbook to create a backup of a file in the remote servers before copy.
This is pretty simple. You can use the below playbook:
– hosts: blocks
tasks:
– name: ansible copy file backup example
copy:
src: ~/helloworld.txt
dest: /tmp
backup: yes
Steps to add multiple servers to ansible master
yum install ansible
sudo amazon-linux-extras install ansible2
ansible –version
[root@ip-172-31-33-11 ec2-user]# pwd
/home/ec2-user
[root@ip-172-31-33-11 ec2-user]# vi abc.pem (copy content of pem files for the machines which we want to connect)
chmod 400 abc.pem
vi inventory.txt
[root@ip-172-31-33-11 ec2-user]# cat inventory.txt
devops
DevOpsInterview ansible_host=65.0.23.22 ansible_connection=ssh ansible_user=ec2-user
DevOpsInterview2 ansible_host=65.0.24.12 ansible_connection=ssh ansible_user=ec2-user
database
DevOpsInterviewdb ansible_host=65.0.23.122 ansible_connection=ssh ansible_user=ec2-user
DevOpsInterviewdb2 ansible_host=65.0.24.132 ansible_connection=ssh ansible_user=ec2-user
ssh-agent bash
cp abc.pem ~/.ssh/
ssh-add ~/.ssh/abc.pem
ansible DevOpsInterview -m ping -i inventory.txt
ansible all -m ping -i inventory.txt
ansible database -m ping -i inventory.txt
Install, start, enable nginx service and then grep nginx version and check nginx service status on host machine using ansible
Create an inventory file (in case don’t want to use inventory .. edit hosts in the file: /etc/ansible/hosts )
Create install_nginx.yaml ( playbook)
# Install Nginx using Ansible
# Start and Enable Nginx
# Check the status of Nginx
– name: Setup Nginx server on myserver list
hosts: myservers
become: True
tasks:
– name: Install the latest version of nginx
command: amazon-linux-extras install nginx1.12=latest -y
args:
creates: /sbin/nginx
– name: Start nginx
service:
name: nginx
state: started
– name: Enable nginx
service:
name: nginx
enabled: yes
– name: Ensure nginx is at the latest version
command: nginx -v
– name: Get status of nginx installed
command: systemctl status nginx
– name: Ansible copy file to remote server
copy:
src: /home/ec2-user/sample.txt
dest: /home/ec2-user
- If using inventory file then Run command :
ansible-playbook install_nginx.yaml -i inventory.txt -v
- If not using inventory file then run command :
ansible-playbook install_nginx.yaml -v