What are the benefits of using version control?
Benefits of using a version control tool:
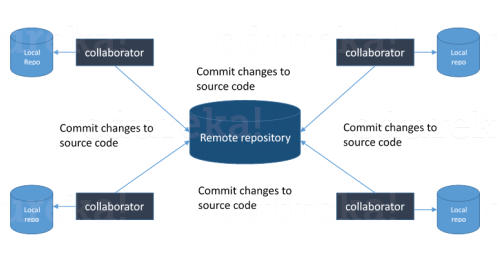
1. With Version Control System (VCS), all the team members are allowed to work freely on any file at any time. VCS will later allow you to merge all the changes into a common version.
2. All the past versions and variants are neatly packed up inside the VCS. When you need it, you can request any version at any time and you’ll have a snapshot of the complete project right at hand.
3. Every time you save a new version of your project, your VCS requires you to provide a short description of what was changed. Additionally, you can see what exactly was changed in the file’s content. This allows you to know who has made what change in the project.
4. A distributed VCS like Git allows all the team members to have the complete history of the project so if there is a breakdown in the central server you can use any of your teammate’s local Git repository.
What is Git?
Git is a Distributed Version Control system (DVCS). It can track changes to a file and allows you to revert back to any particular change.
Its distributed architecture provides many advantages over other Version Control Systems (VCS). One major advantage is that it does not rely on a central server to store all the versions of a project’s files. Instead, every developer “clones” a copy of a repository. The “Local repository” has the full history of the project on the user’s hard drive so when there is a server outage all we need for recovery is one of our teammate’s local Git repositories.
What is the purpose of branching in GIT?
The purpose of branching in GIT is that you can create your own branch and jump between those branches. It will allow you to go to your previous work keeping your recent work intact.
Describe branching strategies (Git-Flow) you have used?
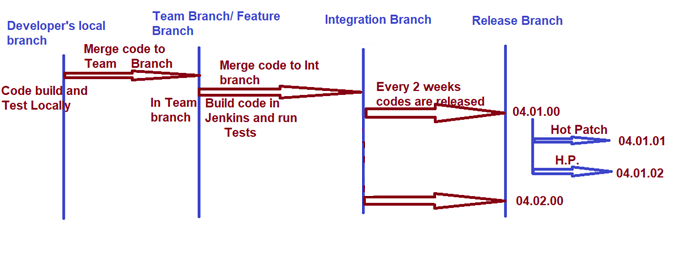
We have various branches for a release. First, developers create branches for their own development purpose, then we have a team or feature branch then we have an integration branch and finally, we have a release and hot patch branch.
The branch created by the developer is for their own development purpose, where he can build and test the change locally. Then he can merge the code changes to the team/feature branch for which the build is set up in Ci- Jenkins.
Whenever code is checked into the team branch, the Jenkins job is triggered, and the entire build/deployment and testing are done. If the build is green, developers can merge the code to the int branch.
The integration branch is a branch where all the team merges their code, and the build for this branch is done 4 times a day. A fully deployable software is created out of this build.
After that we have release branches such as 4.1.0 or 4.20 … release branches are created twice a month i.e., after every fifteen days.
And if required we create a hot patch branch from the release branch as 4.1.1 and 4.1.2 … software created from release/hot-patch branches go to production.
What is the baseline in SCM?
A baseline is a milestone and reference point in software development that is marked by the completion or delivery of one or more predefined products goal.
a baseline is a static (i.e. unchanging) snapshot of the source code tree at any point in time. The purpose of the baseline is to have a static reference point for changes that occur after the baseline is created.
In software development, baselines are created at various planned points in the software development process like code-freeze, product-release, and hotfix. A baseline is also useful when you need to create a “branch” to provide an emergency fix based on some baseline of code that was delivered to a customer. The emergency fix is safely developed in a separate branch away from the “main” development. Regardless of what I do in the branch, the baseline will never be destroyed (i.e. you can always return to a known starting point).
What is Git fork? What is the difference between fork, branch, and clone?
A fork is a remote, server-side copy of a repository, distinct from the original. A fork isn’t a Git concept really, it’s more a political/social idea.
A clone is not a fork; a clone is a local copy of some remote repository. When you clone, you are actually copying the entire source repository, including all the history and branches.
A branch is a mechanism to handle the changes within a single repository in order to eventually merge them with the rest of code. A branch is something that is within a repository. Conceptually, it represents a thread of development.
Explain the advantages of Forking Workflow
The main advantage of the Forking Workflow is that contributions can be integrated without the need for everybody to push to a single central repository that leads to clean project history. Developers push to their own server-side repositories, and only the project maintainer can push to the official repository.
When developers are ready to publish a local commit, they push the commit to their own public repository—not the official one. Then, they file a pull request with the main repository, which lets the project maintainer know that an update is ready to be integrated.
A branch is a lightweight thing that is often temporary and may be deleted. A fork (on github) is a new project that is based on a previous project.
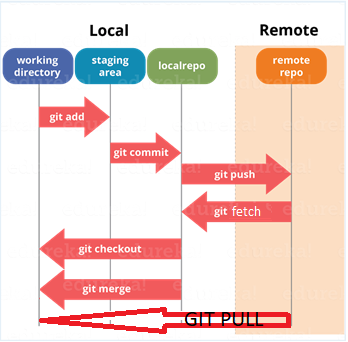
What is the difference between git pull and git fetch?
Git pull = git fetch + git merge
Git pull command pulls new changes or commits from a particular branch from your central repository and updates your target branch in your local repository.
Git fetch is also used for the same purpose, but it works in a slightly different way. When you perform a git fetch, it pulls all new commits from the desired branch and stores it in a new branch in your local repository.
If you want to reflect these changes in your target branch, git fetch must be followed with a git merge. Your target branch will only them updated after merging the target branch and fetched branch.
What is ‘staging area’ or ‘index’ in Git?
Before completing the commits, it can be formatted and reviewed in an intermediate area known as ‘Staging Area’ or ‘Index’. From the diagram it is evident that every change is first verified in the staging area I have termed it as “stage file” and then that change is committed to the repository.
Tell me the difference between a working tree, index, and HEAD in Git?
The working tree/working directory/workspace is the directory tree of (source) files that you see and edit.
The index/staging area is a single, large, binary file in <baseOfRepo>/.git/index, which lists all files in the current branch, their sha1 checksums, time stamps and the file name – it is not another directory with a copy of files in it.
HEAD is a reference to the last commit in the currently checked-out branch.
What is blobs, tags, and revision in GIT
Blobs
Blob stands for Binary Large Object. Each version of a file is represented by
blob. A blob holds the file data but doesn’t contain any metadata about the file.
It is a binary file and in Git database, it is named as SHA1 hash of that file. In
Git, files are not addressed by names. Everything is content-addressed.
Tags
Tag assigns a meaningful name with a specific version in the repository. Tags
are very similar to branches, but the difference is that tags are immutable. It
means, tag is a branch, which nobody intends to modify. Once a tag is created
for a particular commit, even if you create a new commit, it will not be updated.
Usually, developers create tags for product releases.
Revision
Revision represents the version of the source code. Revisions in Git are
represented by commits. These commits are identified by SHA1 secure hashes.
What is “git cherry-pick”?
The command git cherry-pick is typically used to introduce particular commits from one branch within a repository onto a different branch. A common use is to forward- or back-port commits from a maintenance branch to a development branch.
git cherry-pick <commit-hash>
Short example of situation, when you need cherry pick
Consider following scenario. You have two branches.
a) release1 – This branch is going to your customer, but there are still some bugs to be fixed.
b) master – Classic master branch, where you can for example add functionality for release2.
NOW: You fix something in release1. Of course you need this fix also in master. And that is a typical use-case for cherry picking. So cherry pick in this scenario means that you take a commit from release1 branch and include it into the master branch.
git cherry-pick steps are as below.
checkout (switch to) target branch.
git cherry-pick <commit id> ( Here commit id is activity id of another branch. Eg : )
git cherry-pick 9772dd546a3609b06f84b680340fb84c5463264f
push to target branch
What language is used in Git?
Git uses ‘C’ language. GIT is fast, and ‘C’ language makes this possible.
What is the command to write a commit message in Git?
git commit . -m “commit message”
How to create a new branch from any of the existing branches in Git
First change/checkout into the branch from where you want to create a new branch. For example, if you have the following branches:
master
dev
So, if you want to create a new branch called “testing” from the branch, follow the steps:
1. Checkout or change into “master”
git checkout master
2. Now create branch testing from master using the below command
git checkout -b testing
3. Now after working on the testing branch and making changes to files, we can push the testing branch to the remote location.
git push origin testing
In Git how do you revert a commit that has already been pushed and made public?
Remove or fix the bad file in a new commit and push it to the remote repository. This is the most natural way to fix an error.
Once you have made the necessary changes to the file, commit it to the remote repository for that I will use – git commit -m “commit message”
Create a new commit that undoes all changes that were made in the bad commit. to do this I will use a command
git revert <commit-id>
What is Git stash?
Often, when you’ve been working on part of your project, things are in a messy state and you want to switch branches for some time to work on something else. The problem is, you don’t want to commit to half-done work and also you can get back to this point later. The answer to this issue is Git stash.
Stashing takes your working directory that is, your modified tracked files and staged changes, and saves it on a stack of unfinished changes that you can reapply at any time.
What is the function of ‘git stash apply?
When you want to continue working where you have left your work, ‘git stash apply’ command is used to bring back the saved changes onto the working directory.
How do you find a list of files that have changed in a particular commit?
To get a list file that has changed in a particular commit use the below command:
git diff-tree -r {commit-hash}
git diff commit-hash
Given the commit hash, this will list all the files that were changed or added in that commit.
The -r flag makes the command list individual files, rather than collapsing them into root directory names only.
When do you use “git rebase” instead of “git merge”?
Both of these commands are designed to integrate changes from one branch into another branch – they just do it in very different ways.
Consider before merge/rebase:
A <- B <- C [master]
^
\
D <- E [branch]
after git merge master:
A <- B <- C
^ ^
\ \
D <- E <- F
after git rebase master:
A <- B <- C <- D <- E
When to use:
If you have any doubt, use merge.
The choice for rebase or merge based on what you want your history to look like.
More factors to consider:
Rebase destroys the branch and those developers will have broken/inconsistent repositories unless they use git pull –rebase.
Rebase is a destructive operation. That means, if you do not apply it correctly, you could lose committed work and/or break the consistency of other developers’ repositories.
Might you want to revert the merge for any reason? Reverting (as in undoing) a rebase is considerably difficult and/or impossible (if the rebase had conflicts) compared to reverting a merge. If you think there is a chance you will want to revert then use merge.
What is the function of ‘git config’?
Git uses your username to associate commits with an identity. The git config command can be used to change your Git configuration, including your username.
Suppose you want to give a username and email id to associate commit with an identity so that you can know who has made a particular commit. For that I will use:
git config –global user.name “Your Name”: This command will add username.
git config –global user.email “Your E-mail Address”: This command will add email id.
What is a repository in GIT?
A repository contains a directory named .git, where git keeps all of its metadata for the repository. The content of the .git directory are private to git.
How can you create a repository in Git?
To create a repository, create a directory for the project if it does not exist, then run the command “git init”. By running this command .git directory will be created in the project directory.
What does ‘hooks’ consist of in git?
This directory consists of Shell scripts which are activated after running the corresponding Git
commands. For example, git will try to execute the post-commit script after you run a commit.
How do you setup a script to run every time a repository receives new commits through push?
To configure a script to run every time a repository receives new commits through push, one needs to define either a pre-receive, update, or a post-receive hook depending on when exactly the script needs to be triggered.
Pre-receive hook in the destination repository is invoked when commits are pushed to it. Any script bound to this hook will be executed before any references are updated. This is a useful hook to run scripts that help enforce development policies.
Finally, post-receive hook in the repository is invoked after the updates have been accepted into the destination repository. This is an ideal place to configure simple deployment scripts, invoke some continuous integration systems, dispatch notification emails to repository maintainers, etc.
Hooks are local to every Git repository and are not versioned. Scripts can either be created within the hooks directory inside the “.git” directory, or they can be created elsewhere and links to those scripts can be placed within the directory.
How do you configure a Git repository to run code sanity checking tools right before making commits, and preventing them if the test fails?
Sanity or smoke test determines whether it is possible and reasonable to continue testing.
This can be done with a simple script related to the pre-commit hook of the repository. The pre-commit hook is triggered right before a commit is made, even before you are required to enter a commit message. In this script one can run other tools, such as linters and perform sanity checks on the changes being committed into the repository.
Finally, give an example, you can refer the below script:
#!/bin/sh
files=$(git diff –cached –name-only –diff-filter=ACM | grep ‘.go$’)
if [ -z files ]; then
exit 0
fi
unfmtd=$(gofmt -l $files)
if [ -z unfmtd ]; then
exit 0
fi
echo “Some .go files are not fmt’d”
exit 1
This script checks to see if any .go file that is about to be committed needs to be passed through the standard Go source code formatting tool gofmt. By exiting with a non-zero status, the script effectively prevents the commit from being applied to the repository.
How will you know in Git if a branch has already been merged into master?
To know if a branch has been merged into master or not you can use the below commands:
git branch –merged It lists the branches that have been merged into the current branch.
git branch –no-merged It lists the branches that have not been merged.
What is a ‘conflict’ in git?
A ‘conflict’ arises when the commit that has to be merged has some change in one place, and the current commit also has a change at the same place. Git will not be able to predict which change should take precedence.
How can conflict in git be resolved?
There are a few steps that could reduce the steps needed to resolve merge conflicts in Git.
- The easiest way to resolve a conflicted file is to open it and make any necessary changes
- After editing the file, we can use the git add a command to stage the new merged content
- The final step is to create a new commit with the help of the git commit command
- Git will create a new merge commit to finalize the merge
To delete a branch what is the command that is used?
Once your development branch is merged into the main branch, you don’t need
development branch. To delete a branch use, the command
git branch -d <branch>
What is another option for merging in git?
“Rebasing” is an alternative to merging in git.
What is the syntax for “Rebasing” in Git?
The syntax used for rebase is “git rebase [new-commit] “
What is the function of ‘git diff ’ in git?
‘git diff ’ shows the changes between commits, commit and working tree etc.
What is ‘git status’ used for?
As ‘Git Status’ shows you the difference between the working directory and the index, it is helpful in understanding a bit more comprehensively.
What is the function of ‘git checkout’ in git?
A ‘git checkout’ command is used to update directories or specific files in your working tree with those from another branch without merging them in the whole branch.
Git checkout is used to switch to a different branch.
What is the function of ‘git rm’?
To remove the file from the staging area and also off your disk ‘git rm’ is used.
What is the use of ‘git log’?
To find specific commits in your project history- by author, date, content or history ‘git log’ is used.
What is ‘git add’ is used for?
‘git add’ adds file changes in your existing directory to your index.
How to remove a file from git without removing it from your file system?
If you are not careful during a git add, you may end up adding files that you didn’t want to commit. However, git rm will remove it from both your staging area (index), as well as your file system (working tree), which may not be what you want. Instead, use git reset.
The function of ‘Git Reset’ is to reset your index as well as the working directory to the state of your last commit.
git reset filename
This means that git reset <paths> is the opposite of git add <paths>.
- A git revert is a tool for undoing committed changes, while git reset HEAD is for undoing uncommitted changes.
Name a few Git repository hosting services
Pikacode
Visual Studio Online
GitHub
GitEnterprise
SourceForge.net
What is the difference between Git and GitHub?
GitHub is a cloud-based source code repository built around the Git tool. Along with providing a central location from which Git users can push and pull code.
GitHub also adds a variety of services and features that are not native to Git, such as forking, user management, online editing, and branch protection.
What is bitbucket
Bitbucket Server (formerly known as Stash) is a combination Git server and web interface product. It allows users to do basic Git operations (such as reviewing or merging code, similar to GitHub). It also provides integration with other Atlassian tools.
Bitbucket Server is a commercial software product that can be licensed for running on-premises. Atlassian provides Bitbucket Server for free to open source projects meeting certain criteria, and to organizations that are non-profit, non-government, non-academic, non-commercial, non-political, and secular. For academic and commercial customers, the full source code is available under a developer source license.
Reasons Why Developers Should Use Bitbucket
1. SUPERIOR CODE REVIEW
2. JIRA INTEGRATION
3. ACCESS CONTROL PERMISSIONS
4. GREAT INTERFACE
5. UNLIMITED PRIVATE REPOSITORIES
How to delete a Git branch both locally and remotely?
To remove a local branch from your local system.
git branch -d the_local_branch
To remove a remote branch from the server.
git push origin :the_remote_branch
What is Git LFS?
Git is a distributed version control system, meaning the entire history of the repository is transferred to the client during the cloning process.
For projects containing large files, particularly large files that are modified regularly, this initial clone can take a huge amount of time, as every version of every file has to be downloaded by the client.
Git lfs (large file storage) is a git extension developed by atlassian, github, and a few other open source contributors, that reduces the impact of large files in your repository by downloading the relevant versions of them lazily.
Specifically, large files are downloaded during the checkout process rather than during cloning or fetching.
Git lfs does this by replacing large files in your repository with tiny pointer files. During normal usage, you’ll never see these pointer files as they are handled automatically by git lfs.
How to Edit an incorrect commit message in Git?
git commit –amend -m “This is your new git message”
How do you rename the local branch?
git branch -m oldBranchName newBranchName
How do I remove local files (Not in Repo) from my current Git branch?
git clean -f -n
How to Checkout remote Git branch?
git checkout test_branch
Various GIT Commands
git clone repopath : To clone repo in local machine
git add . : To add new file
git status ; git status –short : To check difference between local repo and index
git commit . -m SUP-11490 : To commit file
git push : to push commited changes from local repo to remote repo
git diff . : Command to find file difference
git reset –soft head~1 : command to reset last commit
git config –global user.name “user name”
git config –global user.name “user name” –replace-all (to re-correct username)
git config user.name (to display set git username)
git config –global user.email “user.name@abc.com”
git config –global user.email User.name@abc.com
git config –global –unset user.password (Command to reset your git password)
git checkout new2 (switches to branch new2) : git command to change git branches
GIT command to merge code
git clone “https://User.Name%40ABC.com@giturl.int.abc.com/scm/config/projecta.git”
cd process-code/
git checkout 03.00.00
git pull origin 02.00.00
git status
Merge through source tree .. resolve conflict by selecting .. resolve using theirs .. if you need to keep changes of 02.00.00
git status
git commit
git push origin 03.00.00
git log : check log of a head
git revert
git log data/common/wfm_frontend_builds_map.yml
git revert 6303de402098bfa7f2424c48a4c34019a9389059
git push
Ignoring Files and Folders
You can make Git ignore certain files and directories — that is, exclude them from being tracked by Git — by creating one or more .gitignore files in your repository.
- temporary resources e.g. caches, log files, compiled code, etc.
- local configuration files that should not be shared with other developers
- files containing secret information, such as login passwords, keys and credentials
You can pass filenames on the command line, and git check-ignore will list the filenames that are ignored.
For example:
$ cat .gitignore
*.o
$ git check-ignore example.o Readme.md
example.o
How to show the commit log as a graph in Git:
We can use –graph to get the commit log to show as a graph. Also, –oneline will limit commit messages to a single line.
git log –graph –oneline
How to show the commit log as a graph of all branches in Git:
Does the same as the command above, but for all branches.
git log –graph –oneline –all
How to abort a conflicting merge in Git:
If you want to throw a merge away and start over, you can run the following command:
git merge –abort
How to add a remote repository in Git
This command adds a remote repository to your local repository (just replace https://repo_here with your remote repo URL).
git add remote https://repo_here
How to see remote URLs in Git:
You can see all remote repositories for your local repository with this command:
git remote -v
How to get more info about a remote repo in Git:
Just replace the origin with the name of the remote obtained by running the git remote -v command.
git remote show origin



Hello DE Solutions,
This is a feedback,
I’ve gone through the GIT questions and answers the content is crisp and clear.
The content is great and the website is very informative.
Thankyou.