Find the list of Important DevOps Interview Questions and Answers. Be interview ready by going through these important questions and answers.
What is DevOps? Provide a brief definition and explain why it is important in modern software development practices.
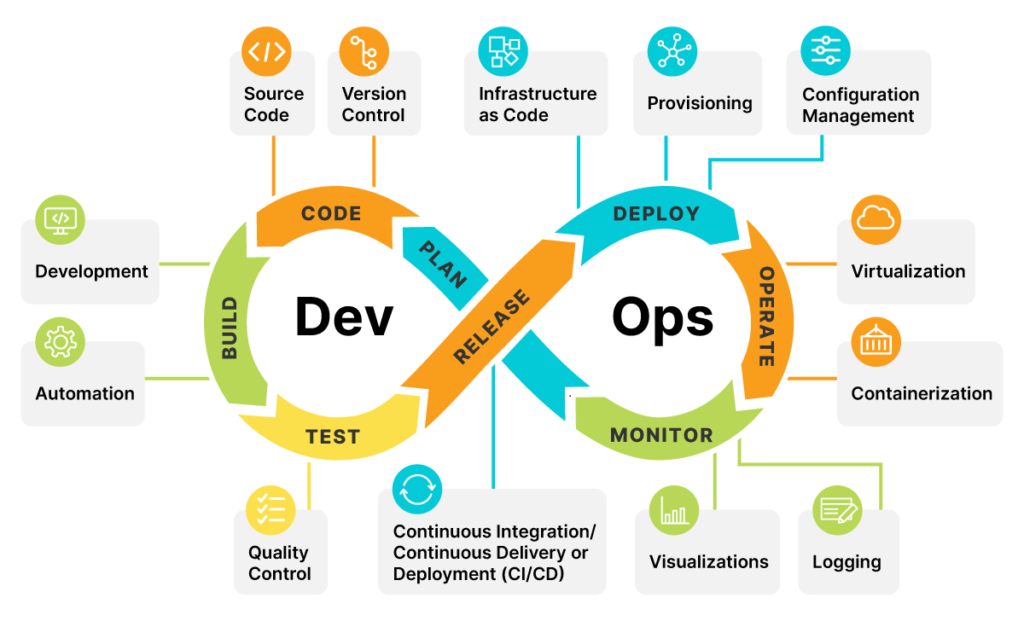
DevOps is a set of practices that combines development and Operations teams to provide continuous delivery with high software quality. DevOps aims to improve the collaboration and communication between development and operations teams, automate processes, and streamline the software delivery pipeline.
It is very important in modern software development practices, because Instead of releasing big sets of features, companies are trying to see if small features can be shipped to their customers. This has many advantages like quick feedback from customers, the better quality of software, etc. which in turn leads to high customer satisfaction. We can achieve this by use of DevOps.
To achieve this companies are required to have a process of
1. Continuous integrations
2. Continuous Delivery in some cases Continuous deployment.
3. Continuous testing.
4. Faster s/w roll-back in the event of a new release crashing
DevOps fulfills all these requirements and helps in achieving seamless software delivery.
Explain the concept of Continuous Integration (CI) and Continuous Deployment (CD) in the context of DevOps. Provide examples of popular tools used for CI/CD and explain their significance.
In DevOps Continuous Integration, Continuous Deployment, and Continuous Delivery are important concepts.
Continuous integration is a DevOps practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run. Continuous integration most often refers to the build or integration stage of the software release process.
Continuous Delivery (CD) is a DevOps practice in which continuous integration and then automated testing is done. We also have automated deployment capabilities and deployment happens in the testing environment for further testing by QA Teams.
Continuous Deployment is a DevOps practice in which continuous integration, automated testing, and continuous deployment to the production server are done. In this every code change goes through the entire pipeline of build, test, and deployment and is put into production, automatically, resulting in many production deployments every day.
With Continuous Delivery, your software is always release-ready, yet the timing of when to push it into production is a business decision, so the final deployment is a manual step. With Continuous Deployment, any updated working version of the application is automatically pushed to production. Continuous Deployment mandates Continuous Delivery, but the opposite is not required.
There are many popular tools used for CI/CD (continuous integration and continuous delivery) that are used by development and operations teams to automate and streamline the software delivery pipeline. Like Jenkins, and Gitlab.
Jenkins – Jenkins is an open-source automation server that is widely used for CI/CD. It supports a wide range of plugins and integrations with other tools, making it highly customizable and versatile. Jenkins can automate the building, testing, and deployment of software, and can be used for projects of all sizes.
Describe the benefits of using Infrastructure as Code (IaC) in DevOps practices. Provide examples of popular IaC tools and explain how they contribute to the automation and scalability of infrastructure provisioning.
Infrastructure as Code (IaC) is a practice in DevOps where infrastructure is defined and managed using code, similar to how applications are developed and managed. Terraform is one of the best tool for infrastructure as code and automation.
IaC provide many benefits like :
Automation: IaC enables automation of infrastructure provisioning, configuration, and deployment. By defining infrastructure as code, developers can automate repetitive tasks, reducing the risk of manual errors and making deployments faster and more reliable.
Consistency: With IaC, infrastructure is defined in code and can be versioned, reviewed, and tested like any other software code. This ensures consistency across environments, making it easier to maintain and troubleshoot infrastructure issues.
Scalability: IaC allows for easy scaling of infrastructure, by defining infrastructure components as code, developers can quickly spin up new instances and deploy applications to meet the needs of growing user demands.
Collaboration: IaC promotes collaboration between development and operations teams. By defining infrastructure as code, developers can easily share infrastructure definitions, collaborate on infrastructure changes, and automate deployment workflows.
Flexibility: IaC allows for easy experimentation with different infrastructure configurations, enabling teams to quickly test and iterate on infrastructure changes.
Faster recovery: In case of failures, IaC allows for faster recovery time, as the infrastructure can be rebuilt and redeployed using the same code.
Overall, IaC is a critical practice in DevOps that helps organizations to improve infrastructure management, increase agility, and accelerate software delivery. By adopting IaC, organizations can achieve faster time-to-market, improve quality, reduce errors, and increase collaboration between development and operations teams.
Terraform is one of the best tool for infrastructure as code and automation.
Discuss the importance of version control in DevOps workflows. Explain why it is essential to use version control systems like Git and how they enable collaboration, traceability, and repeatability in software development and deployment processes.
The importance of using a version control tool in the devops workflow is as mentioned below:
1. With Version Control System (VCS), all the team members are allowed to work freely on any file at any time. VCS will later allow you to merge all the changes into a common version.
2. All the past versions and variants are neatly packed up inside the VCS. When you need it, you can request any version at any time and you’ll have a snapshot of the complete project right at hand.
3. Every time you save a new version of your project, your VCS requires you to provide a short description of what was changed. Additionally, you can see what exactly was changed in the file’s content. This allows you to know who has made what change in the project.
4. A distributed VCS like Git allows all the team members to have the complete history of the project so if there is a breakdown in the central server you can use any of your teammate’s local Git repositories.
It is highly essential to use version control systems like GIT as this provides collaboration as all team members are allowed to work freely on any file at any time. User can then create Pull Request from its development/feature branch to main master/integration branch and can get approval/reviewed.
GIT like version control system also helps in traceability as entire history is maintained and with Commits, users can provide comment which help in identifying the cause for the commits.
How do you ensure security and compliance requirements are addressed in DevOps processes?
Ensuring security and compliance requirements are addressed in DevOps processes is essential to minimize risk and ensure that software is deployed safely and efficiently. A few ways are:
- A set of policies and procedures needs to be documented to be followed across the organization.
- If some third-party jars are being uploaded in the artifactory they should go through proper security vulnerabilities and policy checks.
- A stage should be introduced in the CI-CD pipeline which scans various jars of vulnerabilities and risks, by using checkmarks and blackduck.
- While logging any tool a proper authentication method should be used like using LDAP for logging into Jenkins, sonarqube.
- Enable a secure method for employee login to the AWS console, like using AWS Single Sign-On (SSO) with Multi-Factor Authentication (MFA) enabled.
- Encrypt/store all passwords used in the build, and test flow by storing passwords in the Amazon security manager and Jenkins Credential manager.
- A stage should be introduced which does static code analysis of the product code and notify developers of any vulnerabilities, and risks and get them fixed.
Explain the concept of “shift-left” testing in DevOps and its significance in ensuring quality and stability in software releases. Provide examples of different types of testing and when they should be integrated into the DevOps pipeline.
Shift-left testing is a key concept in DevOps, which refers to the process of moving testing activities earlier in the software development life cycle (SDLC) to catch defects and bugs as early as possible. The goal is to identify issues before they can propagate and cause larger problems downstream.
By identifying bugs and defects earlier and getting them fixed in the initial state, we are ensuring quality and stability in software releases.
In our current organization, we have automated the entire CI-CD flow using Jenkins pipeline, where code checkout, build, publishing jar to artifactory, creation of AWS images using packer, then deployment using terraform and AWS and finally testing is performed. By following this CI-CD cycle twice in 24 hrs and running sanity and P0 tests, we are ensuring that the entire code in the integration/master branch is error/bug-free.
Different types of testing and its integration into the DevOps pipeline are :
Unit Testing: Unit testing is the process of testing individual components of code or functions to ensure they work as expected. This type of testing is usually automated and can be integrated into the developer’s workflow.
Integration Testing: Integration testing is the process of testing how different components of the system work together. It ensures that the system as a whole is functioning as expected. Integration testing should be conducted after unit testing is completed and before moving to system testing. In DevOps cycle after integration build and deployment in testing environment, integration testing is performed. Sanity and P0 testing is performed as part of Int testing in devops cycle.
System Testing: System testing is the process of testing the complete system as a whole to ensure it meets the requirements and specifications. System testing should be conducted after integration testing is completed and before moving to acceptance testing. In my organization, this is not included in CI-CD flow and is done separately by the testing team.
Acceptance Testing: Acceptance testing is the process of testing whether the system meets the customer’s requirements and expectations. This type of testing can be performed either manually or with automated tools. In my organization, this is not included in CI-CD flow and is done separately by the testing team.
Performance Testing: Performance testing is the process of testing the system’s ability to perform under various loads, including high traffic or high transaction volume. Performance testing should be conducted after the system testing is completed. In my organization, this is not included in CI-CD flow and is done separately by the Performance team.
Security Testing: Security testing is the process of testing the system for potential security vulnerabilities and threats. This testing is integrated as a job in CI-CD flow and testing through sonarqube and checkmarks is integrated in the CICD flow.
In general, the testing types mentioned above should be integrated into the DevOps pipeline in a continuous manner, with each testing stage being conducted before moving on to the next stage. By doing so, issues can be caught and resolved earlier in the development process, resulting in higher-quality software and faster delivery times.
Discuss the importance of monitoring and logging in DevOps practices. Explain the key principles of observability and how monitoring and logging enable teams to identify and resolve issues quickly and efficiently.
Monitoring and logging are critical components of DevOps practices, as they provide visibility into the performance and health of the system, help to identify issues, and facilitate rapid problem resolution. Here are some reasons why monitoring and logging are important in DevOps:
Proactive Issue Identification: if the monitoring system detects a spike in traffic, the team can quickly investigate and take measures to ensure the system remains performant.
Rapid Problem Resolution: When issues do occur, logging provides a record of what happened, when it happened, and why it happened. T
Continuous Improvement: Monitoring and logging provide insights into the system’s performance and health over time, allowing teams to identify trends and make data-driven decisions to improve the system.
Compliance and Security: Logging is also essential for compliance and security purposes. Compliance regulations often require organizations to maintain a record of system events and actions, and logging enables organizations to meet these requirements.
In summary, monitoring and logging are critical components of DevOps practices. They provide visibility into the performance and health of the system, help to identify issues, facilitate rapid problem resolution, enable continuous improvement, and ensure compliance and security. By prioritizing monitoring and logging in the DevOps pipeline, organizations can improve system reliability, reduce downtime, and ultimately deliver better products to their users.
The key principles of observability in DevOps can be summarized as follows:
Collecting Relevant Data: Observability requires collecting the right data, at the right time, and from the right sources. This means that organizations must determine what metrics, logs, and traces they need to collect in order to effectively monitor and analyze their systems.
Instrumenting the System: In order to collect the necessary data, organizations must instrument their systems with the appropriate tools and frameworks.
Correlating Data: To gain insights into the system’s behavior, organizations must be able to correlate data from different sources. This means integrating data from metrics, logs, and traces to gain a comprehensive view of the system’s performance and behavior.
Analyzing Data: Once data has been collected and correlated, organizations must be able to analyze it in a meaningful way. This involves using tools and techniques such as visualization, alerting, and anomaly detection to identify patterns and anomalies in the data.
Acting on Insights: The ultimate goal of observability is to identify issues and take action to resolve them. This requires having a clear understanding of the system’s behavior and performance, and the ability to quickly respond to issues as they arise.
Overall, the key principles of observability in DevOps are focused on collecting, correlating, analyzing, and acting on data in order to gain insights into the system’s behavior and performance. By following these principles, organizations can effectively monitor and analyze their systems, identify and resolve issues quickly, and ultimately deliver better products to their users.
Describe the concept of “Infrastructure as a Service” (IaaS) and “Platform as a Service” (PaaS) in cloud computing and explain their relevance in modern DevOps practices. Provide examples of popular IaaS and PaaS providers and their use cases.
Infrastructure as a Service (IaaS) is a type of cloud computing service that offers essential computing, storage, and networking resources on demand, on a pay-as-you-go basis. Eg- AWS-ec2.
Platform as a Service (PaaS) provides a runtime environment. It allows programmers to easily create, test, run, and deploy web applications. Eg- aws elastic beanstalk.
IaaS (Infrastructure as a Service) and PaaS (Platform as a Service) are two key components of modern DevOps practices. Both IaaS and PaaS offer significant advantages in terms of flexibility, scalability, and cost-effectiveness, which can help organizations to streamline their DevOps processes and improve their overall software development lifecycle.
IaaS is beneficial for DevOps teams, who need to be able to quickly spin up new environments and resources to support their development and testing processes.
By using PaaS, developers can focus on building their applications, without having to worry about the underlying infrastructure or the complexities of managing and scaling their applications. This is beneficial for DevOps teams, who need to be able to rapidly develop and deploy new applications and features in response to changing business needs.
In both cases, IaaS and PaaS can help organizations to streamline their DevOps processes, by providing rapid access to infrastructure and services, reducing the time and effort required to deploy and manage applications, and improving the overall agility and flexibility of the development process. By using IaaS and PaaS in combination with other DevOps practices such as automation, continuous integration and continuous delivery, organizations can significantly improve their ability to deliver high-quality software quickly and efficiently.
Explain the concept of “Immutable Infrastructure” in DevOps and its benefits in terms of scalability, reliability, and security. Provide examples of tools and techniques used to achieve immutable infrastructure.
In DevOps, “immutable infrastructure” refers to an infrastructure design and deployment approach in which infrastructure components are treated as immutable, meaning they are never modified after they are created. Instead, changes to the infrastructure are made by creating new components and replacing the old ones. This approach offers several benefits in terms of scalability, reliability, and security.
One key benefit of immutable infrastructure is that it makes it easier to scale infrastructure up and down as needed. Since new components can be easily created and destroyed, it is simple to add or remove resources based on changes in demand. This makes it possible to quickly respond to changes in workload, which can improve the overall performance and efficiency of the system.
Another benefit of immutable infrastructure is that it can improve the reliability of the system. Since components are never modified after they are created, there is less chance of configuration drift or other issues that can arise when components are modified over time. This can reduce the risk of unexpected downtime or other issues that can impact the availability of the system.
Finally, immutable infrastructure can also improve security by making it more difficult for attackers to compromise the system. Since components are never modified, there is less chance of introducing vulnerabilities or other security issues into the system over time. Additionally, since components are created from a known configuration, it is easier to ensure that they are configured securely from the outset.
To achieve immutable infrastructure, DevOps teams use a range of tools and techniques, including:
Infrastructure as Code (IaC): Infrastructure as Code is a technique that involves defining infrastructure components using code, typically in a configuration language such as Terraform or CloudFormation. This makes it easy to create new components from a known configuration, which is an essential part of immutable infrastructure.
Containerization: Containerization technologies such as Docker can be used to package applications and dependencies into isolated containers. Since containers are immutable by design, they can be easily replaced or scaled as needed.
Orchestration tools: Orchestration tools such as Kubernetes can be used to manage containerized infrastructure components, making it easy to scale up or down as needed.
Continuous Integration and Continuous Deployment (CI/CD): Continuous Integration and Continuous Deployment pipelines can be used to automate the deployment of new infrastructure components, ensuring that they are always created from a known configuration.
By using these tools and techniques, DevOps teams can achieve immutable infrastructure, which can offer significant benefits in terms of scalability, reliability, and security.
Discuss the importance of security in DevOps practices. Explain the concept of “DevSecOps” and why it is crucial to integrate security considerations throughout the software development lifecycle.
Security is a critical consideration in modern DevOps practices, given the increasing prevalence of cyber attacks and data breaches. In order to protect sensitive data and ensure the integrity of software systems, it is essential to integrate security considerations throughout the entire software development lifecycle. This is where the concept of “DevSecOps” comes into play.
DevSecOps is a set of practices that emphasizes the importance of integrating security into every stage of the software development lifecycle, from planning and design through to deployment and maintenance. This means that security considerations are not an afterthought, but are instead an integral part of the development process from the outset.
One of the key reasons why DevSecOps is crucial is that it helps to identify and mitigate security risks early in the development process, before they can become major issues. By incorporating security testing and analysis into the development pipeline, DevOps teams can identify potential vulnerabilities and address them before they are deployed into production. This can help to reduce the risk of data breaches and other security incidents, and can also save time and effort by preventing the need to fix security issues at a later stage.
Describe the key principles of DevOps culture, including collaboration, automation, measurement, and sharing. Explain why these principles are important and how they contribute to successful DevOps implementations.
DevOps culture is founded on a set of principles that emphasize collaboration, automation, measurement, and sharing. These principles are crucial to the success of DevOps implementations because they help to create a culture that supports rapid and reliable software delivery, continuous improvement, and the alignment of IT goals with business objectives.
Collaboration: Collaboration is one of the key principles of DevOps culture. It involves breaking down silos between different teams and departments, and promoting cross-functional collaboration throughout the software development lifecycle.
Automation: Automation is another important principle of DevOps culture. By automating repetitive and time-consuming tasks, DevOps teams can speed up software delivery, reduce the risk of human error, and increase efficiency.
Measurement: Measurement is a principle of DevOps culture that emphasizes the importance of collecting and analyzing data in order to gain insights into the performance of the software development process. By measuring key metrics such as lead time, deployment frequency, and mean time to recover (MTTR), DevOps teams can identify areas for improvement, track progress over time, and make data-driven decisions that support continuous improvement.
Sharing: Sharing is a principle of DevOps culture that emphasizes the importance of knowledge sharing and collaboration across different teams and departments. By sharing knowledge and best practices, DevOps teams can increase their collective expertise, reduce duplication of effort, and promote a culture of continuous learning and improvement.
Together, these principles form the foundation of a DevOps culture that supports rapid and reliable software delivery, continuous improvement, and the alignment of IT goals with business objectives. By promoting collaboration, automation, measurement, and sharing, DevOps teams can create a culture that supports innovation, agility, and the delivery of value to customers.
Scenario: Deploying a Web Application
You are tasked with deploying a web application on a cloud-based infrastructure using a CI/CD pipeline. The application consists of a front end developed in Angular and a back-end developed in Node.js. The application uses a PostgreSQL database as its data store.
Test Case:
Describe the steps you would take to set up an automated CI/CD pipeline for the web application, from code repository to production deployment.
Which tools or technologies would you use to implement the CI/CD pipeline, and why?
I will use below tools/ technologies to implement the CI/CD pipeline:
Git, Bitbucket – as a version control tool
Jenkins – As Continuous Integration – Continuous Deployment Tool – Scripted or Declarative Pipeline jobs.
Selenium – Continuous Testing Tool
Ansible – Configuration Management tool
Jfrog Artifactory – to store artifacts.
Terraform – to manage infrastructure as a code
Sonarqube – as a static code analysis tool.
Packer –as a packaging tool, Docker & AWS AMI can be created using Packer.
AWS – Cloud computing tool for deployment
CloudWatch/ grafana and Prometheus – as a continuous monitoring tool
Docker – containerization Tool
Kubernetes (EKS) – Container orchestration Tool
These are the best tools available for CI/CD pipeline and I have working experience with these tools.
How would you ensure that the application is securely deployed, including appropriate access controls, encryption, and vulnerability scanning?
To ensure that an application is securely deployed, there are several best practices that should be followed. Here are some key steps:
Implement appropriate access controls: This involves configuring the appropriate user permissions and roles to access the application, as well as ensuring that sensitive data is protected through proper authentication. This can be achieved through the use of tools like AWS Identity and Access Management (IAM).
Enable encryption: This involves implementing encryption protocols to protect data both at rest and in transit. This can be achieved by using encryption tools like AWS Key Management Service (KMS) and SSL/TLS certificates.
Conduct vulnerability scanning: Regular vulnerability scanning can help identify potential security weaknesses and ensure that application is secure against known vulnerabilities. As mentioned earlier we can use tools like checkmarks, Blackduck for security vulnerability scanning.
Regularly update and patch software: Regularly updating and patching software can help ensure that known security vulnerabilities are addressed and that the application is protected against potential attacks.
Implement security monitoring and logging: Monitoring and logging can help identify potential security breaches and allow for quick response to any incidents. This can be achieved through the use of tools like AWS CloudTrail and Amazon CloudWatch.
How would you handle database schema changes during the deployment process to ensure data integrity and minimize downtime?
Handling database schema changes during deployment can be a challenging task, as it requires careful planning to ensure that data integrity is maintained and downtime is minimized. Here are some best practices that can help in handling database schema changes during the deployment process:
Use version control for database schema: Version control is essential to keep track of changes made to the database schema. It helps to identify changes that are made during the deployment process, and also roll back changes if something goes wrong.
Perform schema changes in stages: It is best to perform schema changes in stages, rather than doing everything at once. This can help to minimize downtime and reduce the risk of errors.
Create backups before deploying changes: Before making any changes to the database schema, it is important to create a backup of the current database. This ensures that if anything goes wrong during the deployment process, the original data can be restored.
Use a blue-green deployment strategy: A blue-green deployment strategy can help to minimize downtime during the deployment process. This involves creating a duplicate environment with the new schema changes and switching over to the new environment once it has been fully tested.
By following these best practices, we can handle database schema changes during the deployment process while ensuring data integrity and minimizing downtime.
How would you monitor the deployed application for performance, availability, and error rates? What tools or techniques would you use?
Monitoring the performance, availability, and error rates of a deployed application is critical to ensure that it is functioning correctly and meeting the needs of its users. Here are some tools and techniques that can be used to monitor an application:
Use an application performance monitoring (APM) tool: APM tools such as New Relic, Datadog, and AppDynamics can provide real-time monitoring of an application’s performance, including response times, throughput, and error rates. These tools can also help to identify performance bottlenecks and other issues that can affect the application’s availability.
Implement logging and error tracking: Logging and error tracking can help to identify issues with the application, such as slow response times or errors. Tools such as Loggly, Splunk, and ELK Stack can be used to aggregate and analyze log data, while tools like Sentry and Rollbar can be used to track and analyze errors.
Use synthetic monitoring: Synthetic monitoring involves simulating user interactions with an application to monitor its availability and performance. Tools like Pingdom and Uptrends can be used to set up synthetic monitoring tests for an application.
Monitor infrastructure: Infrastructure monitoring tools such as Nagios, Zabbix, and Prometheus can be used to monitor the underlying infrastructure that supports the application, including servers, databases, and networking components.
Set up alerts: It’s important to set up alerts to notify administrators when issues are detected with the application. This can be done using tools such as PagerDuty, OpsGenie, or Slack.
By using these tools and techniques, it is possible to monitor an application for performance, availability, and error rates. This can help to ensure that the application is functioning correctly and meeting the needs of its users.
Describe how you would handle an incident where the application goes down after deployment. What steps would you take to identify and resolve the issue quickly?
First of all, I will use a deployment strategy with the least downtime .. like Rolling deployment or blue-green deployment. By using these deployments if the application goes down after deployment, we can quickly roll back to the previous deployment having short downtime and min user impact.
Also, the application going down after deployment is a critical issue that needs to be resolved quickly to minimize the impact on users. Here are some steps that I will take to identify and resolve the issue:
Notify stakeholders: The first step is to notify all stakeholders, including developers, operations teams, and business users, that the application is down. This can be done via email, messaging tools, or phone calls.
Check system status: Check the status of the underlying infrastructure, including servers, databases, and networking components, to ensure that they are all up and running.
Check application logs: Check the application logs to identify any errors or issues that may have caused the outage. This can help to pinpoint the root cause of the problem.
Roll back changes
Conduct a post-mortem analysis: Once the incident has been resolved, conduct a post-mortem analysis (RCA) to identify the root cause of the issue and determine what steps can be taken to prevent similar incidents from happening in the future.
Communicate with stakeholders: Once the incident has been resolved and a post-mortem analysis has been conducted, communicate the findings and any steps taken to prevent similar incidents to stakeholders.
How would you manage configuration and environment variables for the application, such as database connection strings, API keys, and other sensitive information?
Managing configuration and environment variables is an essential part of deploying and managing an application.
I generally recommend using secure key-value stores to store secrets such as API keys, database connection strings, and other sensitive information. AWS Secrets Manager can be used to securely store secrets.
Various credentials used in Jenkins jobs can be stored in Jenkins credential manager.
I also implement access controls – Implementing access controls to ensure that only authorized users can access sensitive information and configuration settings.
How would you handle versioning and release management of the application to ensure smooth deployments and rollbacks, if needed?
Proper versioning and release management are critical for ensuring smooth deployments and rollbacks of an application. Here are some best practices for
managing versioning and releases:
Use semantic versioning: Use semantic versioning to identify the version of the application. Semantic versioning involves using a three-part version number that includes a major version number, a minor version number, and a patch number. The major version number is incremented when there are major changes to the application, the minor version number is incremented when new features are added, and the patch number is incremented for bug fixes.
In my current org, we use version like 02.00.00, 02.01.00 , 02.01.05 and for
development purpose we use r9integ, r8integ and so on.
Use a version control system: Use a version control system like Git to manage changes to the application’s source code. This allows for easy tracking of changes and the ability to revert to previous versions if needed.
Use a release management tool: Use a release management tool like Jenkins to automate the process of building, testing, and deploying new versions of the application. This helps to ensure that each release is properly tested before deployment and reduces the risk of errors or issues during deployment.
Automate deployments: Automate the deployment process using tools like packer, terraform, AWS to ensure consistent and repeatable deployments. This also makes it easier to roll back to a previous version if needed.
Conduct thorough testing: Before releasing a new version of the application, conduct thorough testing to identify and fix any issues before deployment. This can include unit tests, integration tests, and end-to-end tests.
Plan for rollbacks: Plan for rollbacks in case something goes wrong during deployment. This can include having a backup plan and ensuring that all versions of the application are properly tagged and stored.
By following these best practices, it is possible to manage the versioning and releases of an application in a way that ensures smooth deployments and rollbacks if needed. This helps to minimize downtime and ensure that the application is functioning correctly for users.
Describe your approach to handling backups and disaster recovery for the application and its underlying infrastructure.
My approach to handling backups and disaster recovery for the application and its underlying infrastructure is to Implement high availability and multi-region architecture, by using AWS services like Elastic Load Balancing, Amazon Route 53, and Auto Scaling. This helps to ensure that the application is always available and can tolerate failures.
I can also use various AWS services to backup, restore, and for disaster recovery like – AWS Backup, and AWS Disaster Recovery.
I will use Amazon S3 for backup storage as S3 is a highly durable and scalable object storage service that can be used to store backups. It allows to define of retention policies, lifecycle rules, and versioning to manage backup data.
How would you collaborate with development, operations, and other stakeholders to ensure a smooth and efficient deployment process?
I will establish clear communication channels to ensure that all stakeholders are aware of the deployment process, including timelines, responsibilities, and potential risks. This can include regular meetings, emails, and other forms of communication. I will establish a clear deployment process that outlines the steps involved in deploying the application, including testing, validation, and rollbacks. This should be documented and communicated to all stakeholders.
I will also work for continuous improvement in the deployment process. I will be taking regular feedback from stakeholders and monitoring performance metrics, and implementing changes based on lessons learned.